
These days, a number of businesses have a requirement to get data from varied sources and store the voluminous data of any type at a single destination. This data can be later used for providing data-driven decisions. Azure Data Lake Gen 2 is being used as a popular choice to serve this purpose.
However, it can be a daunting task for a solution provider to identify the aspects to be considered while designing their first Azure Data Lake. Though, there is no perfect solution as it varies with the business requirement and provided scenario, still there are some generic parameters that can be looked upon.
In this article I will provide insight on what the Azure Data Lake Gen 2 is and recommend best practice for efficient use.
Azure Data Lake Gen 2 or ADLS gen2, is an evolution of Data Lake Storage Gen1 built on top of Blob storage with hierarchical namespace. It's a cloud based big data storage that serves as a storage account for structured, semi-structured and unstructured data.
The data of any type and size can be collected from a number of data sources, stored into ADL and from there the data can be further transformed and analysed.
These are some implementation best practices for efficient use of Azure Data Lake Gen 2 services:
The number of environments varies depending on the project constraints. However, having separate DEV and PROD environments is preferable. This will limit the risk of loss of data in case of accidental drops or unwanted amendments performed.
Most organisations leverage the disaster recovery options available to them on Azure to ensure they are properly protected in case of a data centre outage. As per the requirement, any of these can be selected: ZRS, GZRS, or GRS & RA-GRS.
However, if records are accidentally deleted, that deletion is also replicated. To protect against such events, you should consider having a separate back-up area over the same data lake storage account.
The folder structure shall be as follows:
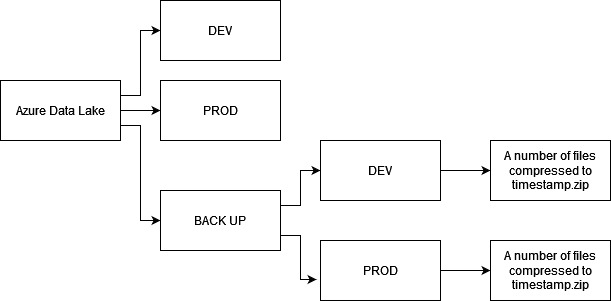
Also, we shall enable soft deletion and set minimal number of days to 7. Soft deletion allows us to retrieve back the data that was accidentally dropped, in our case, within the last 7 days.
3. Data layers
Data layers are recommended, only if there is a strong business requirement to transform the raw data to be more business friendly or the type of data needs cleansing.
Data can be stored in two layers:
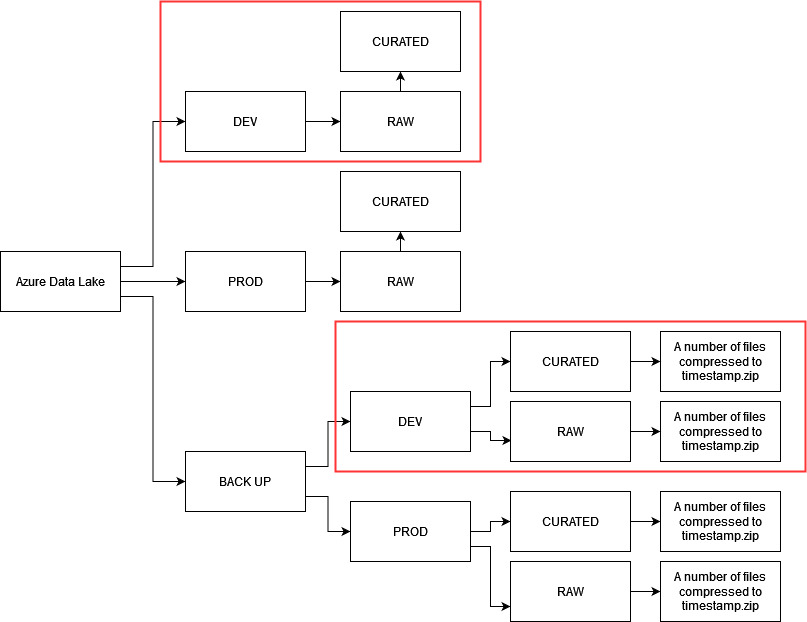
NOTE: Once UAT is performed and PROD environment is readily being used, we can opt to stop refreshing the DEV environment as it will help in cost optimisation or if required, we can continue refreshing both DEV and PROD environments.
If we stop refreshing the DEV environment for cost efficiencies, we need to plan to synch the DEV environment from PROD periodically.
4. Directory Layout
The directory layout depends upon the business requirement. It can be based on:
Time series directory layout is the preferred one as it enables us to retrieve the latest data and easily traverse back in time to retrieve the required dataset.
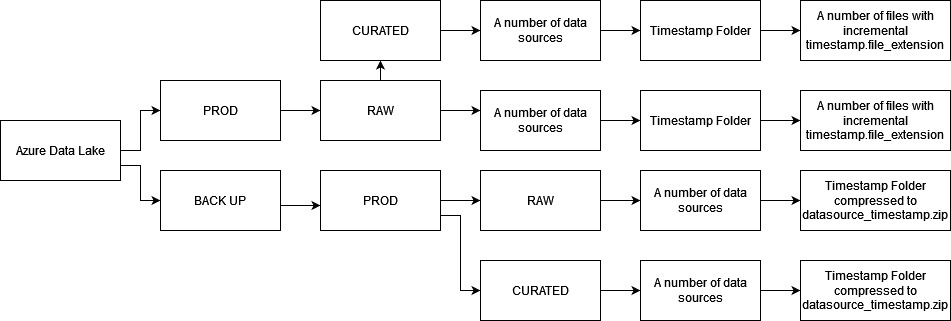
For better understanding, let us consider the following examples:
Similarly, we can have the folder structure for curated layer.
5. Roles and Permissions
Azure Data Lake supports Role-based Access Control (RBAC) and Access Control Lists (ACL) which can be achieved through integration with Azure Active Directory (AAD). RBAC controls access to storage accounts and containers whereas ACL is associated with directories and files.
Hence, we can control who can have access to data in DEV, PROD or Backup container and furthermore, break down access to file level. As a best practice, it is advised to assign security principals with RBAC role on the Storage Account/Container level and to then proceed with the restrictive and selective ACLs on the directory and file level.
6. Cost Optimisation
Azure Data Lake is economical in nature, it has no upfront cost and follows pay-per-use model. The cost depends upon
It is a good practice to calculate and estimate the cost involved before the commencement of the project. Cost estimation can be performed using Azure price calculator.
REFERENCES
Follow the ADL Best practices: https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-best-practices
Copyright © Tridant Pty Ltd.