
I investigated the performance of Snowflake on data sets of various sizes like TPCH_SF1 (approx. 6 million rows) and TPCH_SF10 (approx. 60 million rows) using Tableau.
The benchmark test was conducted to assess timely access to business data through Tableau with a live connection to Snowflake. The process, options and results will be of interest to organisations planning to migrate their data and analytics workloads to the cloud, organisations with their workloads already in the cloud but experiencing scalability or cost concerns, and teams facing performance issues with their extract refreshes.
First, a little bit about Snowflake and its architecture which will help us to better understand the benchmark tests.
Snowflake is an analytic data warehouse that has been designed for the cloud and is a true software-as-a-service (SaaS) offering:
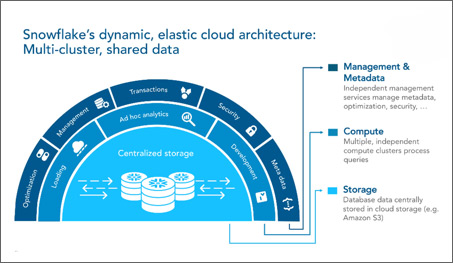
The 3 layers shown in the Snowflake architecture diagram above are:
If the compute layer is the brawn of Snowflake, then the services layer is the brain.
The services layer authenticates user sessions, provides management, enforces security functions, performs query compilation and optimization, and coordinates all transactions. The services layer is constructed of stateless compute resources, running across multiple availability zones and utilising a highly available, distributed metadata store for global state management.
The compute layer is designed to process enormous quantities of data with maximum speed and efficiency.
All data processing muscle and horsepower within Snowflake is performed by virtual warehouses or compute engines, which are one or more clusters of compute resources. When performing a query, virtual warehouses retrieve the minimum data required from the storage layer to satisfy queries. As data is retrieved, it is cached locally with computing resources, along with the caching of query results, to improve the performance of future queries.
Built on scalable cloud blob storage, the storage layer holds all the diverse data, tables and query results for Snowflake. Maximum scalability, elasticity, and performance capacity for data warehousing and analytics are assured since the storage layer is engineered to scale completely independent of compute resources.
As a result, Snowflake delivers unique capabilities such as the ability to process data loading or unloading, without impacting running queries and other workloads.
The separation of services from storage and compute allows multiple virtual warehouses, or compute clusters, to simultaneously operate on the same data. Concurrency is virtually unlimited and can be instantly scaled with a multi-cluster warehouse.
I used 2 of the TPC-H data sets exposed as a Snowflake Data Share using the SNOWFLAKE_SAMPLE_DATA Schema. Both data sets have Orders & Order Line Items by Customer, Parts Region and Supplier.
The data sets were:
I used 2 separate virtual warehouses sized as X-Small and Large for this test.
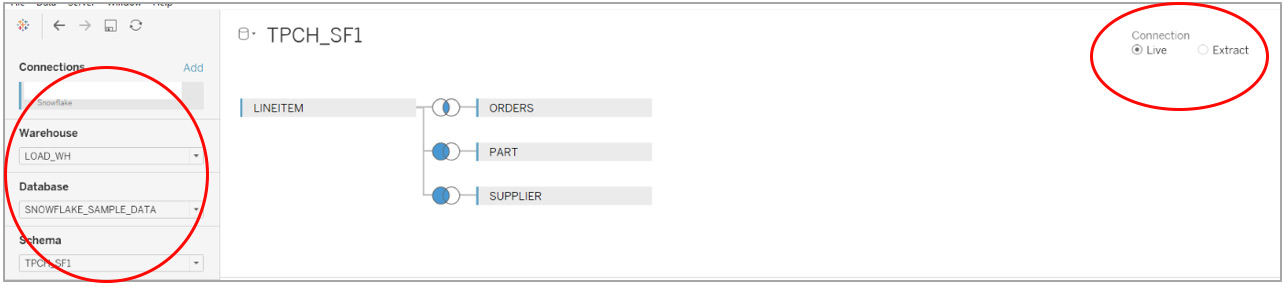
Tableau is connected to Snowflake using the Snowflake provided native connector (Tableau Desktop > Connect > Snowflake).
In all these tests, I kept a Tableau Live Connection to Snowflake to help understand and showcase Snowflake’s power to process and return large amounts of data or process complex queries on the fly. This test, if successful, will put forth the case of real-time data analysis using Snowflake.
Using a Single Cluster, X-Small Virtual Warehouse (1 server per cluster)
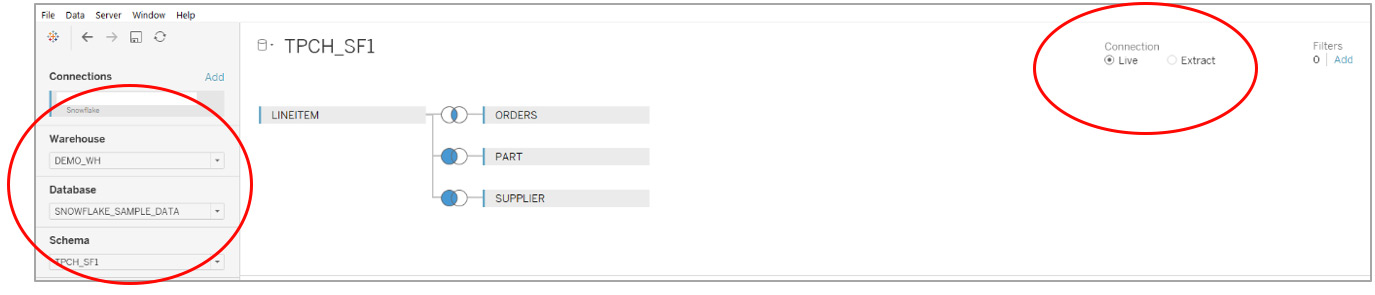
The data source setup in Tableau for the TPCH_SF1 data source is shown in the screenshot below. In this test, I used a X-Small (extra small) virtual warehouse called DEMO_WH.
I then built a simple dashboard in Tableau with a focus on trying to return a large number of data points.
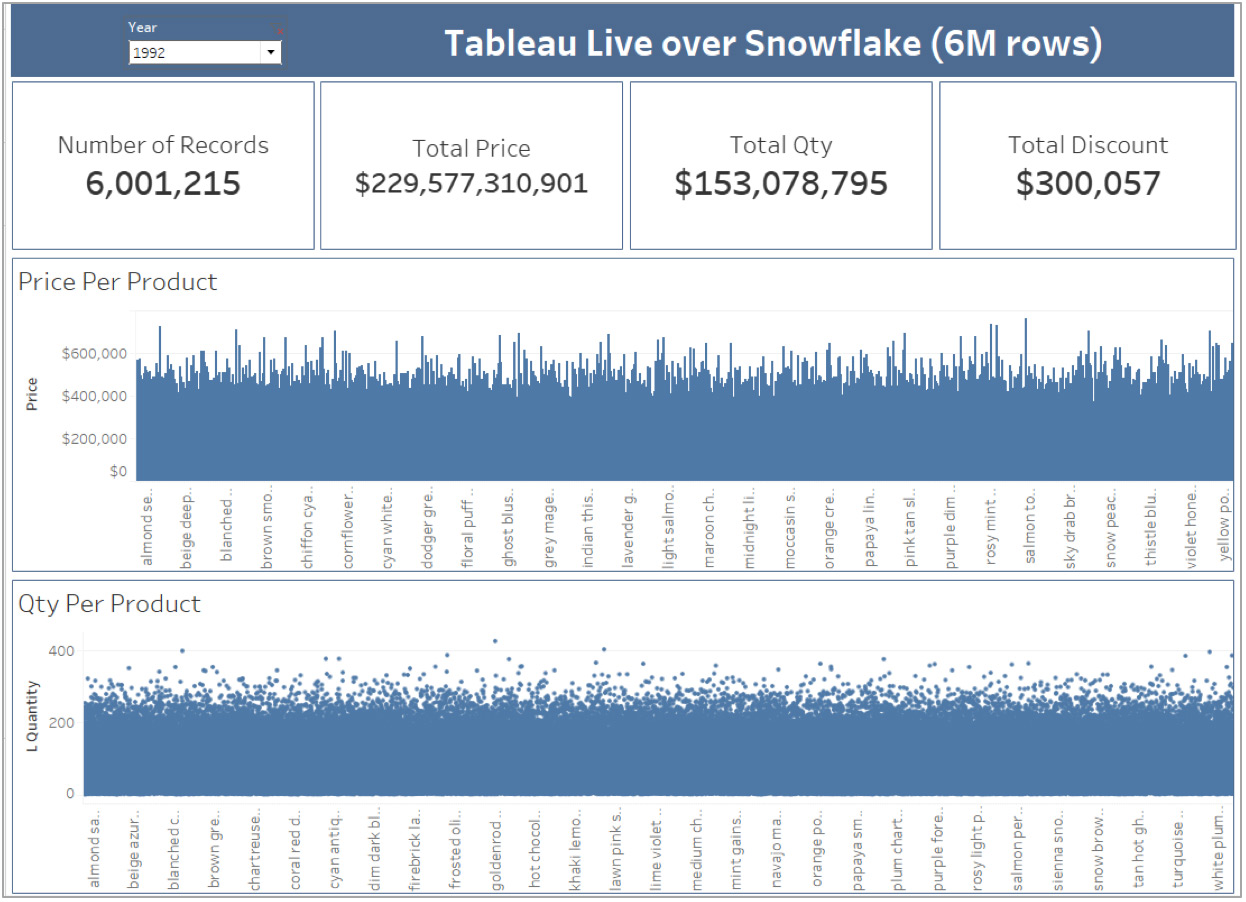
In Tableau, this Dashboard renders itself in about 10 seconds.
Let’s look under the hood into Snowflake. Using Snowflake’s History feature, I noted the time it took Snowflake to process the query that Tableau sent across.
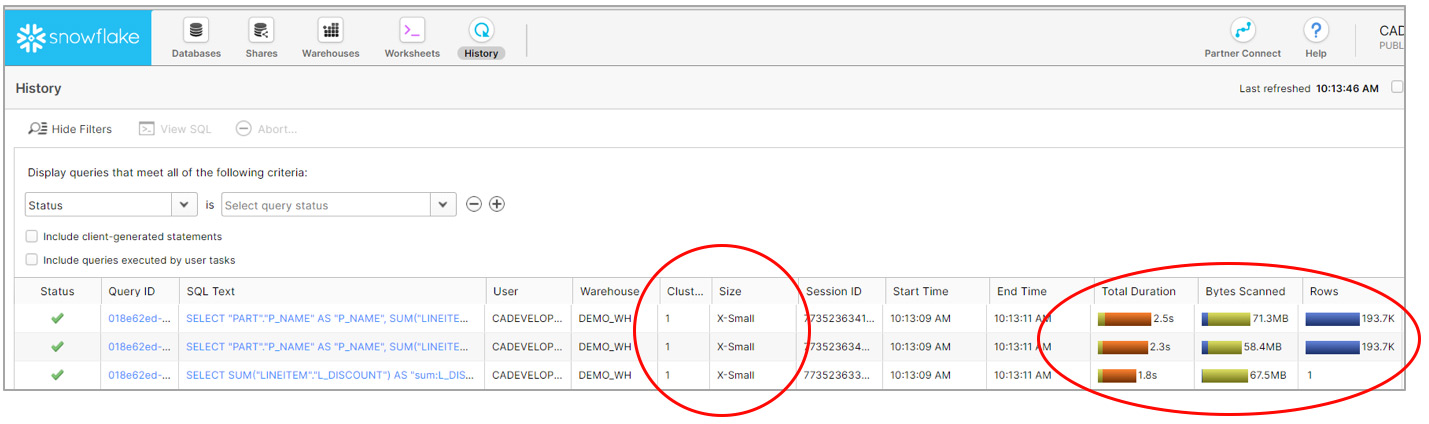
As you can see, Snowflake processed the query in a total of 2.5 seconds with about 71MB scanned, and more importantly 193K rows returned. You can also see that it was executed on a single cluster X-Small virtual warehouse.
I then refreshed Tableau to bring in the same results again. This time, the queries were processed much faster (in milliseconds) and this can happen due to 2 reasons:
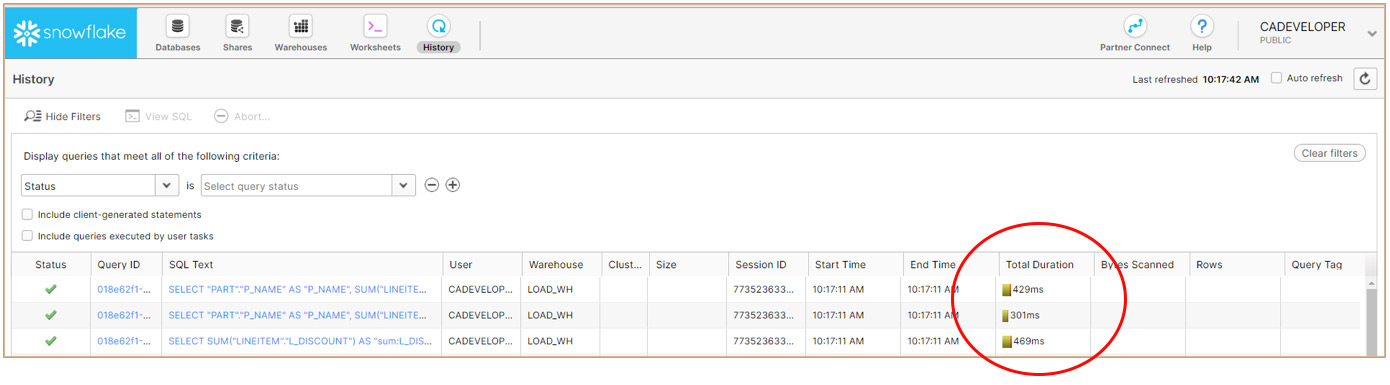
Note: There are no bytes scanned, no rows processed, and no virtual warehouse used as the result set cache was used to return the results.
Using a Single Cluster, Large Virtual Warehouse (8 servers per cluster)
To see the impact a size of the virtual warehouse can have on query run times in Snowflake, I used a different virtual warehouse in this test called LOAD_DW which is a Large virtual warehouse.
The Tableau Dashboard was refreshed and this time I changed the Year filter in the dashboard so that the Result Set cache is not used (The number of records for this year are similar to the previous test).
The query performance in Snowflake is shown below:

The performance in this case was better than in Part 1 of the test with the X-Small warehouse (2.0secs vs 2.5 secs). This is the expected behaviour as increasing the warehouse size should ideally improve the query performance in Snowflake.
In this test, I used the TPCH_SF10 data source which has about 60 million rows in the Line Item table.
Screenshots below show the performance of Snowflake across a X-Small warehouse vs the Result Set Cache vs a Large warehouse:
Snowflake performance using X-Small warehouse:
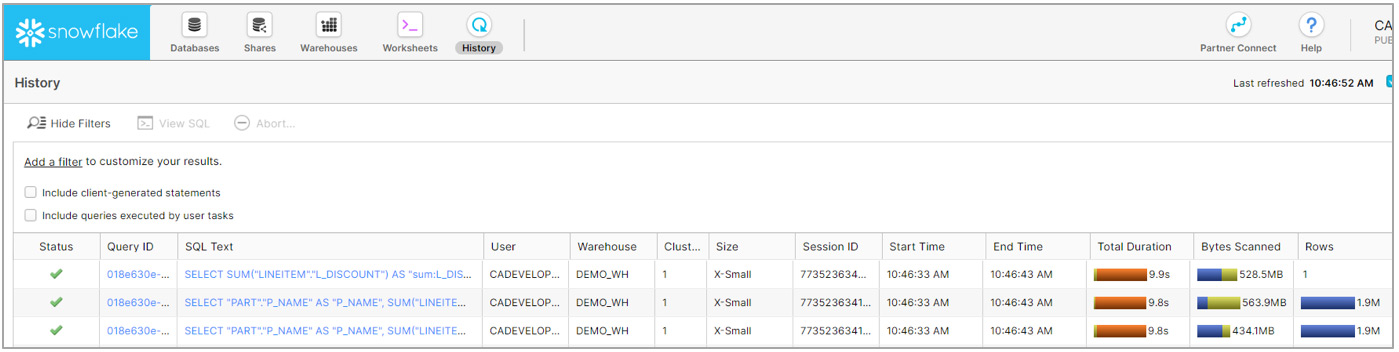
Snowflake performance using Result Set Cache:
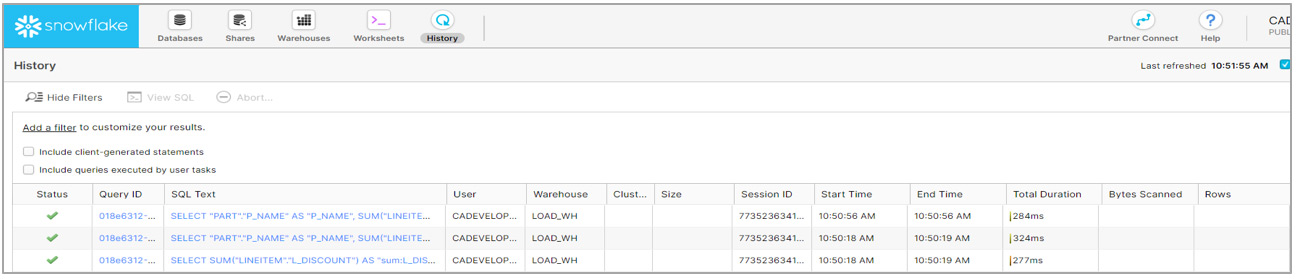
Snowflake performance using Large virtual warehouse:

As you can see, the Large warehouse gives significantly better performance (2.5 secs vs 9.9 secs) over a X-Small warehouse.
Let me quickly reiterate the benchmark setup parameters for the benchmark testing:
My conclusions are:
1. Snowflake was able to process and return a large amount of data in a short time frame. This allows for real-time analysis of your business data on the fly.
2. The ability of Snowflake to return data quickly allows you to maintain a Live Connection in Tableau and this in turn provides the following benefits:
3. With a smaller data set and the nature of the query, the virtual warehouse size may not make a significant difference on your query performance. However, with a larger data set or a complex query, the virtual warehouse size is likely to have a significant impact on your query performance.
4. With many concurrent users and a large number of complex queries, you may also want to consider a multi-cluster warehouse and have it automatically scale, up or down, as needed.
5. If the exact same data is requested out of Snowflake (i.e. firing the the exact same query) by the same user on multiple occasions or by multiple users, Snowflake will use the Result Set Cache to return the results much faster than it would without the cache.
For organisations seeking to analyse many, large and varied data sets, with timely access to their business data, this how-to and benchmark testing surfaces the partnership and synergy of the Snowflake and Tableau tools with respect to performance, simplicity and scalability.
Give your analytics users more real-time access and more modelling capabilities, fast.
Get your business data ready.
Oswald Almeida | Michelle Susay
Copyright © Tridant Pty Ltd.