
Most of the available clinical data is in a narrative form resulting from transcription of dictation or direct entry by doctors. This raw-text format is popular in expressing clinical contents for expert readers, but is troublesome for automated searching, summarization, statistical analysis or decision-support. Constructing structured information from unstructured text can reduce much of the human effort in processing the digital information available in health information systems today. In addition, there has been an increased demand for using a structured form of the clinical record to improve the quality of health care service through decision support, epidemiology and disease surveillance. Using the structured and classified electronic clinical records, doctors and medical staff can have instant access to accurate and relevant information about patients. The combination of this information with reasoning based on the extracted content can help doctors make better decisions about medications and treatments.
This is a step-by-step approach to build a Query by Example search system while utilising MS Azure cloud services for a rapid solution deployment.

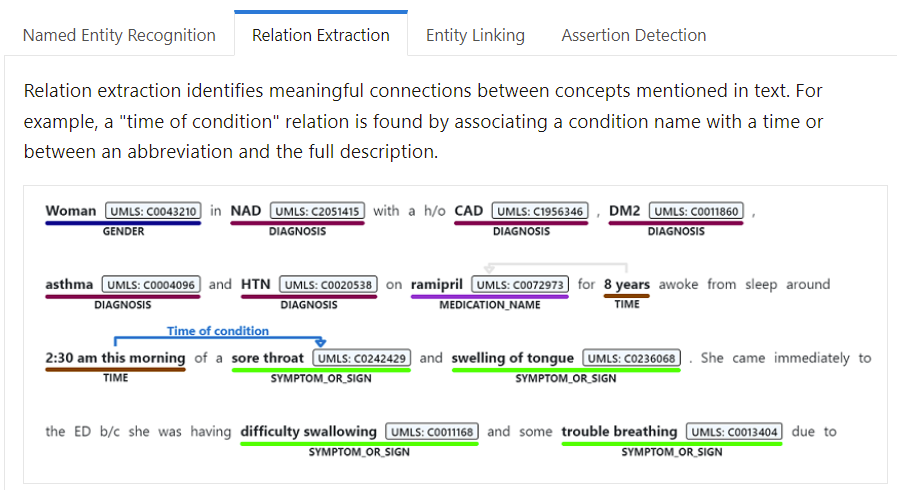
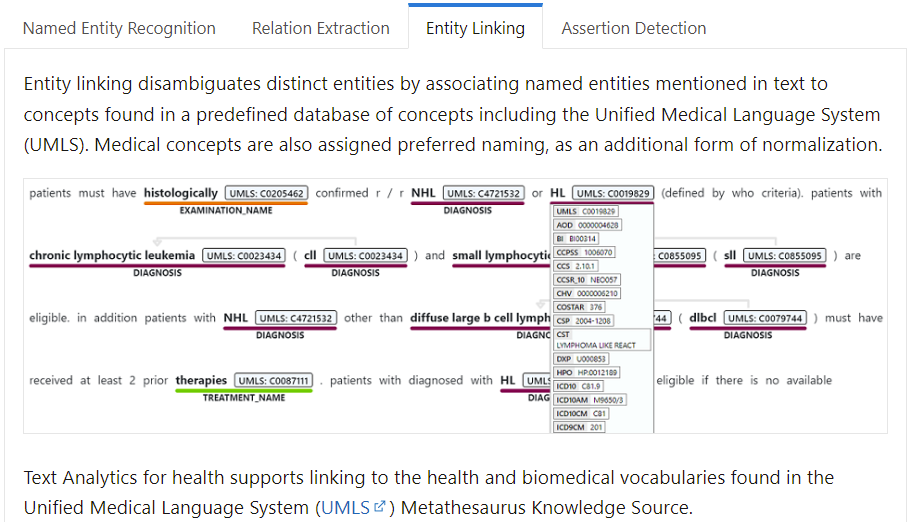
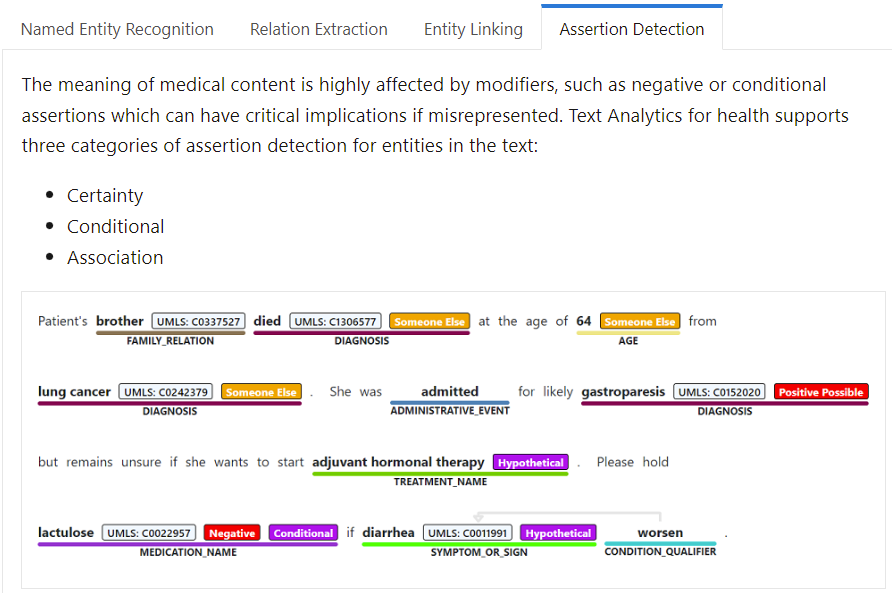
Figure 1. MS Azure health text analyses service.
Azure Cognitive Service for Language provides a cloud-based collection of machine learning and AI algorithms for developing intelligent applications that involve written language, including Text Analytics for health. Text Analytics for health annotates relevant medical information from unstructured texts such as doctor's notes, discharge summaries, clinical documents, and electronic health records.
These annotated contents are Named Entity Recognition (entity is a medical concept), relation between entities, entity linking, and assertion detection as presented in Figure 1.
Have you ever experienced a search system that allows users to input an example to find all relevant instances? For example, to search for all medicine and doses given for a patient, we just need to input an example of this relationship, e.g. “500mg or Panadol” and retrieve all relevant information including “3cc of Ropivacaine” and “16cc of MultiHance”. In general, it is not necessary for the search results to contain any of the keywords mentioned in the query. We do not have this interesting capability from traditional search systems like Google or Bing where the results usually contain at least one keyword.
In many daily search use cases, it is possibly more convenient to be able to provide an example of the information we are looking for rather than using key words search or even concepts search. Firstly, it can be difficult to provide a full list of keywords to look for given some keywords are unknown at time of search. Secondly, concept search is only practical to experts with good understanding of clinical schema while example can be given without full knowledge of relevant results.
You may hear about “Query by Example” for the first time, but the implementation idea is generally simple. The search system just needs to understand the query at the same level as the raw text data was analysed and indexed. For example, what are the concepts or relations mentioned in the query? Then we will be able to look for same instances indexed in the database with offset to reference back to original documents. The implementation processes are described in Figure 2.
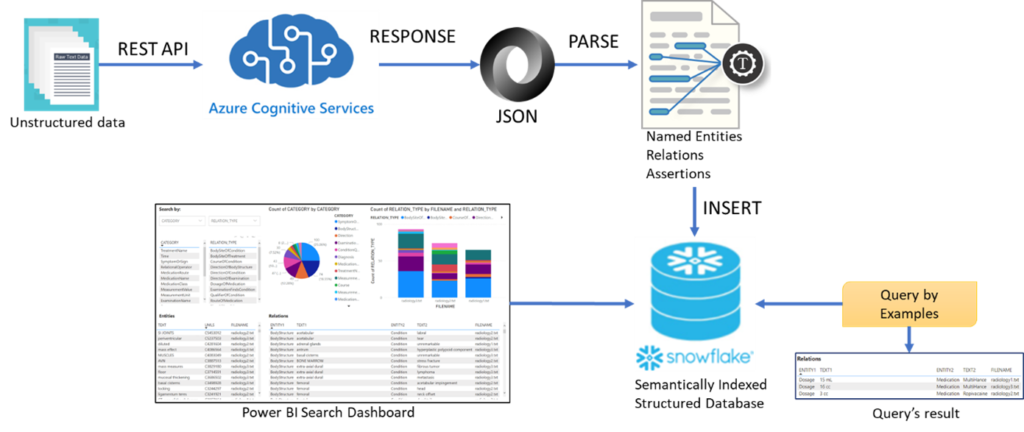
Figure 2. Query by Example and Search dashboard implementation workflow for clinical data.
To enable fast search mechanism, the unstructured clinical data (e.g. patient notes, radiology, pathology reports) should be pre-processed at the time data entering the warehouse and maintain the up-to-date Indexing tables in the data warehouse. Similar to keywords search, when users enter search queries, the system will only need to look at these Index tables to extract results rather than do an intensive on-demand search over the whole database.
The annotation and indexing process for “Query by example” of clinical reports is described in Figure 2. Firstly, raw text reports will be sent to Azure Cognitive Services using REST API for annotation of relevant medical information. Azure is able to process multiple reports in a batch request and the responses are in JSON format with entities information and confident scores of language model (Figure 3). The JSON responses should be parsed, and annotated data will be stored in structured Index Tables in the database. Figure 4 illustrates an example of Index Table using SnowFlake data warehouse. The Index Tables will be updated when new data arrives, or old data is removed from the warehouse. After the semantic Indexing Tables are created, the system is ready for constructing concepts and relations dashboard or example search.

Figure 3. Example JSON response from Azure cognitive service.
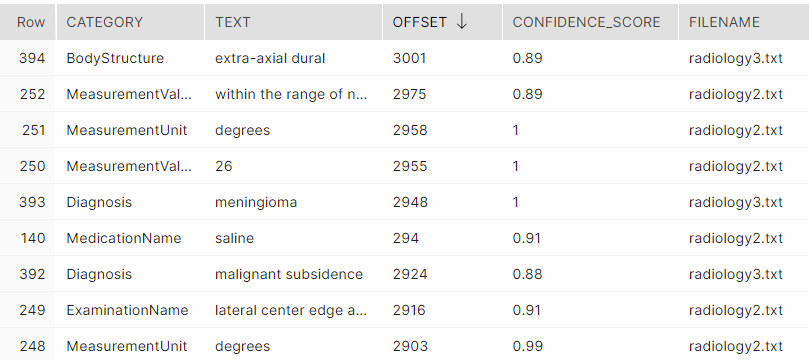
Figure 4. Example of index table for clinical annotations.
As discussed earlier, query parsing follows the same process of indexing, user’s queries should also be posted to Azure cognitive services to identify any concepts or relations within given example. In case user inputs “500mg of Panadol”, Azure health text language service will analyse the query and return two entities: Dosage and MedicationName, and the relationship between them is DosageOfMedication (Figure 5).
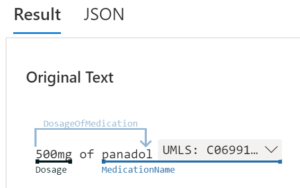
Figure 5. Query annotation by Azure health text language service
By looking up the DosageOfMedication instances in the Relation Index Table, the system will display all relevant relations and their corresponding mentioned reports. Again, all instances of dosage given for a medication are presented with all unseen keywords, this function can be considered as a knowledge discovery process on a semantically indexed database.

Figure 6. Search results of query “500mg of Panadol”
“Query by Example” could be useful for people with basic clinical knowledge who are able to provide simple medical items they are looking for. In case of practitioners or researchers who are more familiar with clinical terms, a search dashboard that supports category (entities) and relation types would be more efficient (Figure 7). The dashboard does not require additional Azure cognitive service request to process the query, therefore it is faster and easier for experienced medical staff.
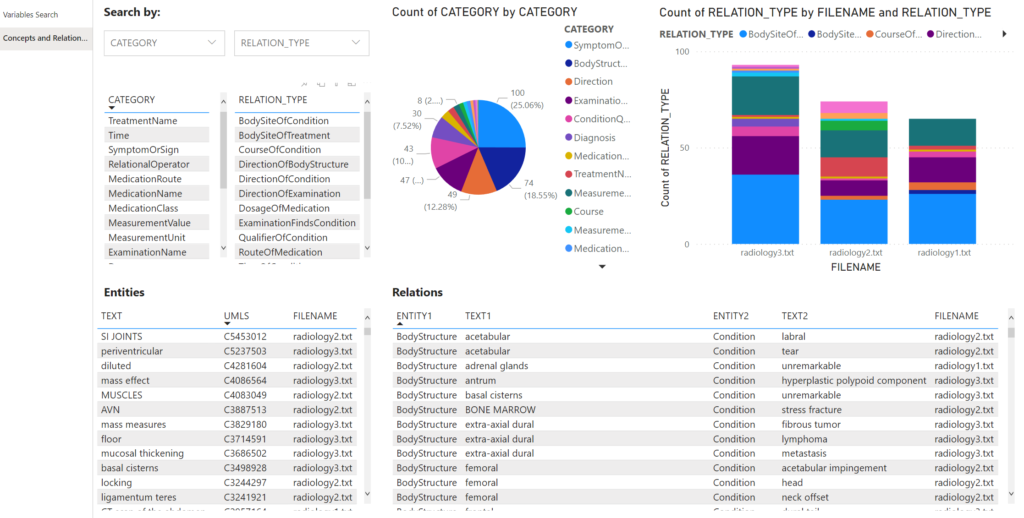
Figure 7. Clinical semantic search dashboard.
This blog describes a novel use case to utilise modern cloud AI services for semantic information extraction and decision support in clinical domain. Using the same mechanism, similar systems can be deployed in just hours for general text or speech processing use cases. 12 years ago, we had been training our own text analytics models for automatic processing of clinical data during my PhD research at university. It is wonderful to see these semantic annotation services available on cloud for instance solution development. However, no solution fits all use cases. If you have ideas or just data and want to gain insights or build novel applications, please get in touch with us.
Copyright © Tridant Pty Ltd.