Recently, there's been a global race in leveraging AI for improving business operations and solving emerging challenges. The rapid increasing number of customers and their associated transaction data has resulted in exceeding costs for maintaining in-house data warehouses and predictive services, especially when the need for scaling up the whole system occurs more often. Data cloud services including Snowflake, AWS Redshift and Azure Data Factory are powered by an advanced data platform provided as Software-as-a-Service (SaaS) to address this business demand.
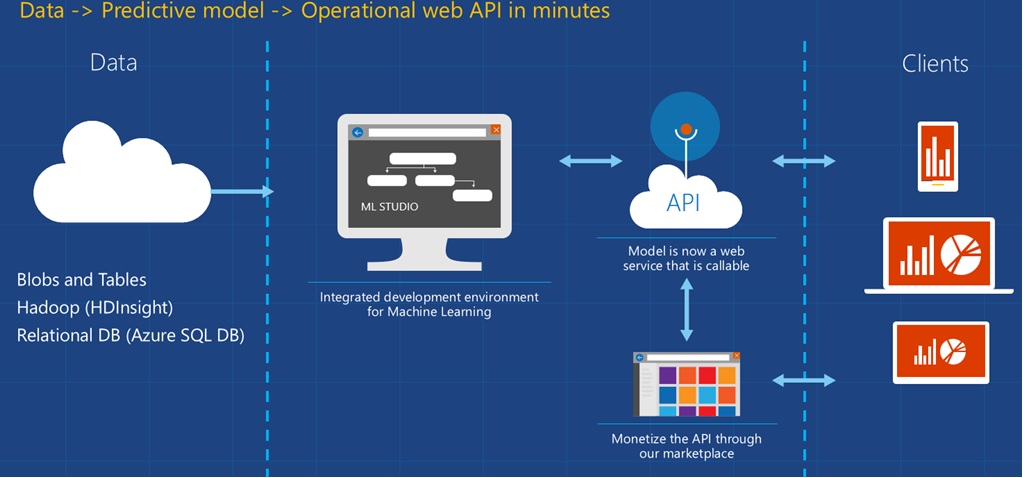
As data is moving into serverless services, it's essential to have analytics and predictive services integrated in the same manner, i.e. a cloud platform. In this blog I will discuss how AI and predictive analytics are provided by the leading vendors, considering different customer segments (organisation sizes and data science backgrounds). Figure 1 presents an example of a cloud-based predictive analytics solution.
In a review, Harvard Business defined data scientist as the sexiest job of the 21st Century 1. With increasing demand for this job, the industry has defined a new kind of data scientist, the citizen data scientist, which according to Gartner is a person who creates or generates models that leverage predictive or prescriptive analytics, but whose primary job function is outside the field of statistics and analytics. Citizen data scientists are becoming more popular than traditional data scientists for many companies, therefore they have been considered as a new customer segment for cloud predictive analytics to be implemented at small and mid-size organisations without the need to maintain the data science team. This is one of the reasons for the major vendors to bring AutoML/AutoAI into the table along with Web Studio (e.g. IBM Watson Studio, MS Azure Studio, AWS Sagemaker Studio, Google Cloud AutoML) to support citizen data scientists who may have limited coding experience. The full services, of course, are still strongly supporting traditional data scientists for the whole AI/ML lifecycle (e.g. using Python SDK). In short, predictive analytics on cloud is now for all levels of data scientists, from beginner to expert.
For example, IBM provides a Watson Studio with two different streams for AutoAI and AutoML. AutoML is mostly targeted for citizen data scientists or data scientists working on standard/common data science scenarios which require rapid testing and deployment of predictive models. The ML tasks within AutoML include:
MS Azure Studio and Google Cloud Platform use a single term AutoML but classified the settings to configure automated ML experiments by the Studio Web Experience or the Python SDK (with full support). Providing similar capability, AWS SageMaker named the service as Autopilot.
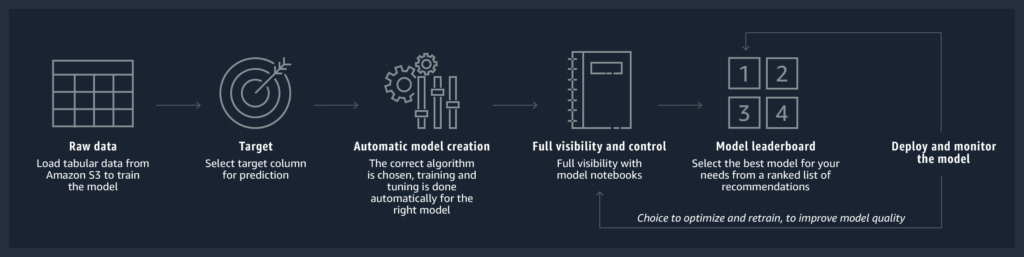
You read it right, one-click deployment is just a single click (maybe a few) to have a prediction model in production. Simply load your csv dataset, specify the target prediction column then… boom you’ll have your prediction model trained and deployed on the cloud End-point. The End-point will be serving as a REST API for predicting incoming data. This process is illustrated by AWS SageMaker in Figure 2.
One-click deployment generally provides a rapid, black-box solution for newbie citizen data scientists. These cloud systems still allow experienced machine learning engineers to have full control and visibility of the features and models. For example, with added customisations, MS Azure ML designer (drag-n-drop ML) supports step-by-step definition and connections of different standard components within a ML workflow (Figure 3).
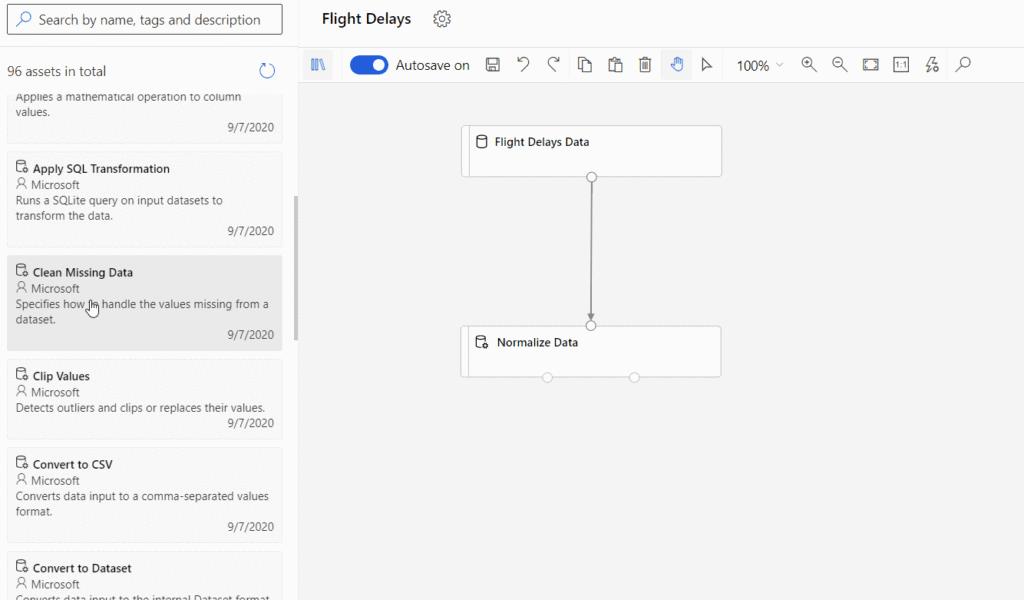
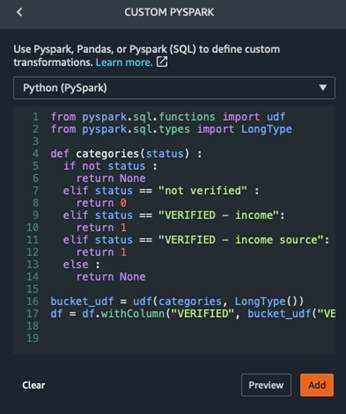
To utilise the ML designer, basic understanding of ML flow including feature engineering, model training, evaluation and deployment is required. However, individual components are still considered as black boxes. Full visibility and control are only achieved by being able to access the code. Most major cloud vendors support generating model notebooks or allow scripting at any stage of the flow. Figure 3 presents the capability to define a custom data transformation using Python, Pandas or Pyspark (SQL) within the feature engineering pipeline.
With basic knowledge of coding and machine learning, citizen data scientists and junior data scientists will be able to utilise web interface ML flow designer provided by major cloud vendors to perform standard predictive analytics tasks which are suitable to small and mid-size businesses. In terms of customer acquisition, we can also recognise a common trend among the leading vendors to shift targets toward these customer segments to bring ML/AI analytics to every business. The easier the service can be used, the more customers the vendors can get.
If you feel you could be a good candidate for a citizen data scientist and are ready to model your data in no time, most top cloud providers offer attractive free tiers/subscriptions to test their systems. Pick one and validate it yourself.
For traditional customers including large organisations with an experienced data science team, cloud vendors support complete ML/AI lifecycle development and monitoring. What they added to the market is the integrated development environment to cover popular aspects of data science and AI. For example, on top of AutoML, IBM AutoAI has the capability to generate code to reimplement the automatic pipeline and additional functions for model testing and scoring. Other capabilities include:
Another example of the ML ecosystem is presented in Figure 4 with Google Cloud Platform.
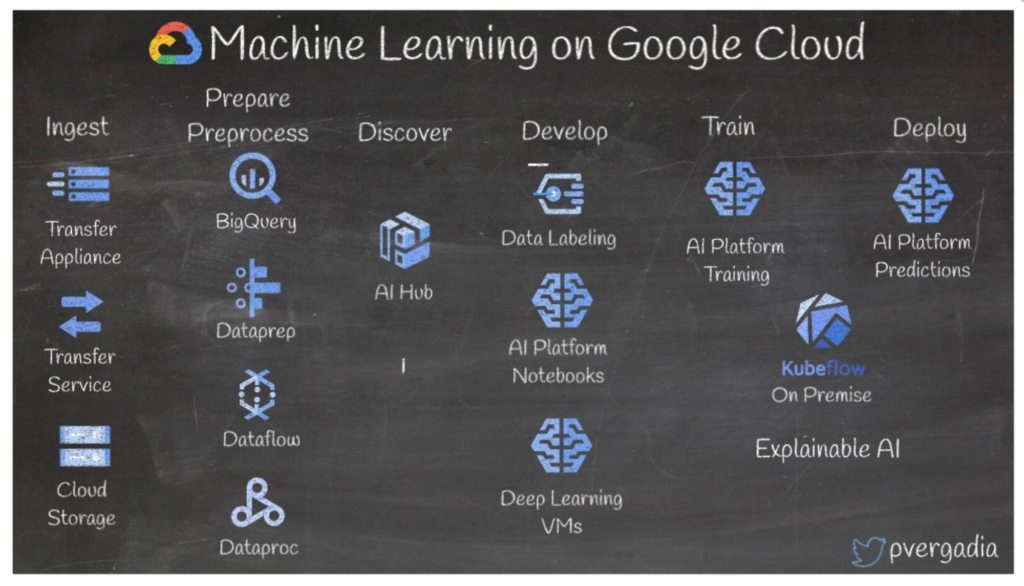
Integrated development environment includes online Jupyter notebooks running on a preconfigured kernels and a selected computing instance. Notebooks are now considered as a standard tool and a must-have capability for major vendors. Advanced features can be listed as built-in web IDE (AWS SageMaker) or Azure Extension on Visual Studio Code. Not to mention that Git is fully supported which makes the cloud system feel like home for machine learning engineers.
Git is there for code (notebooks) version control. However, in data science, there are three other components which also require efficient management, e.g. environments, datasets, experiments and models. Git is only for code as it will not version any file larger than 50Mb, while ML models could be a few Gbs.
The environment includes the base Python and all required library packages (version) to execute the experiments. With Anaconda and Docker configuration embedded, cloud services provide an efficient way to manage and re-produce the experiments. It's good practice to avoid inconsistency between experiment and deployment due to differences in individual library versions.
Figure 6 shows how to manage required library in the cloud environments.

Dataset management and versioning is important to understand a ML model. We need to know which data it has been trained on. Fortunately, dataset version registrations can easily be done on cloud services. Offering more than that, some vendors allow you to set up a data observer to address data drift issues and automatically retrain the model when there are statistically significant changes in the referenced dataset.
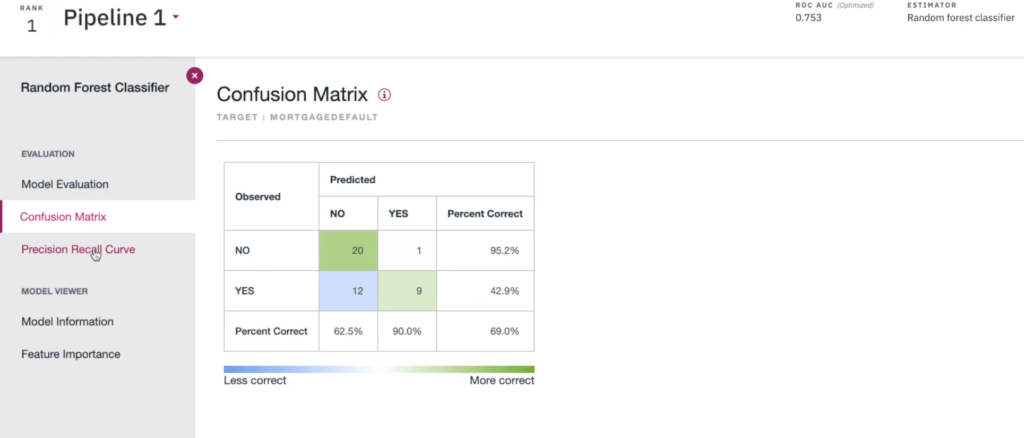
Finally, experiment and model versioning allows data scientists to mange pipeline experiments and models that are used in production. We can configure to use the latest model or in case the model is automatically retrained, we define specific metrics to choose the best model. When an experiment is executed and a model is registered, data scientists can review all hyper parameters and performance metrics. Popular visualisations are also provided including the ROC curve, scatter, and confusion matrix. Figure 6 illustrates the model evaluation outcomes from IBM Watson.
It's exciting to see the cloud service providers considered privacy, fairness and explainable ML as part of their system’s analytic capabilities. Privacy is always important and should never been left aside from any analytics, especially with consumer data. The key question here is how to present the data/result without disclosing any customer privacy? Providers such as MS Azure enables the use of SmartNoise library to generate artificial noise into the data while preserving the underlying distribution of individual features. This will help to maintain both privacy and model prediction performance.
Besides privacy, the ML model can display unfair behaviour which may have an impact on people. The common harms are:
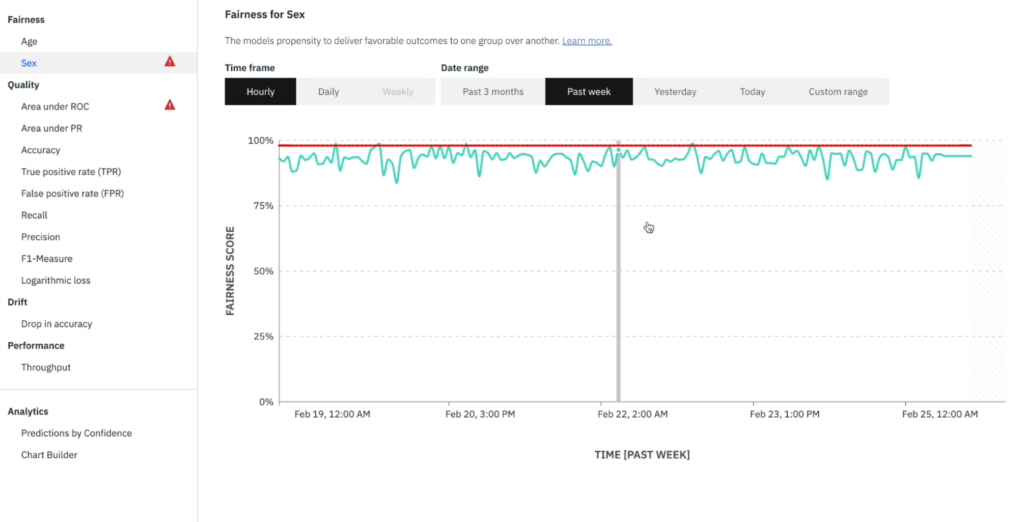
To address this issue, cloud service providers consider Fairlearn which is an open-source Python package that allows machine learning system developers to assess their systems' fairness and mitigate unfairness. Figure 7 shows a fairness analysis from IBM Watson for age and sex attributes.
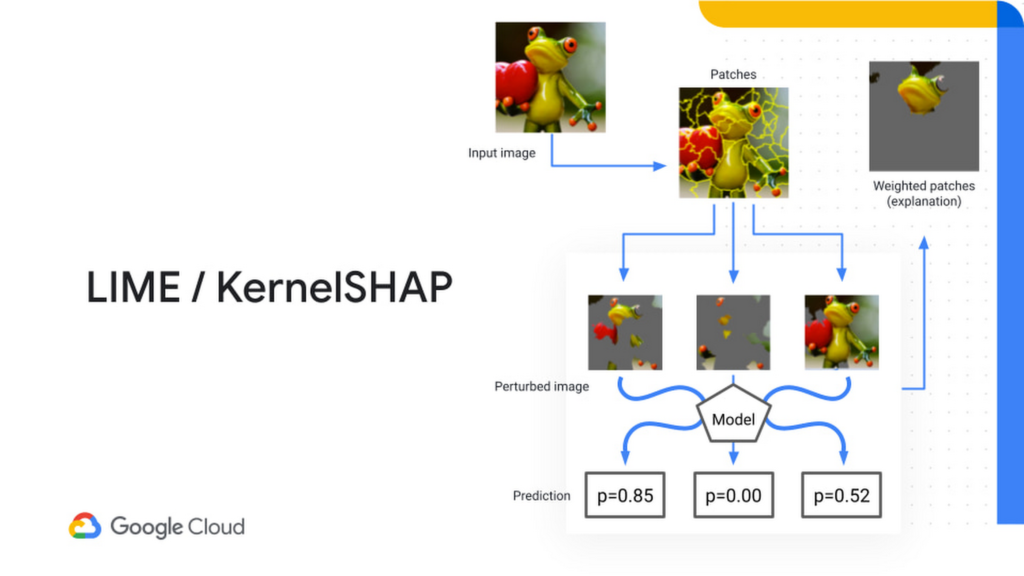
In many cases, the client will ask how did the model make this prediction and why should we trust it? Explainable ML helps to communicate the prediction outcome to the client by analysing how each feature in a row of data contributed to the predicted result. This process can also be referred as feature attribution or feature important ranking and can be done at local or global scopes3:
Figure 9 illustrate a Kernel SHAP method from Google Cloud for explanation of important feature when classifying images.
Backing up behind the rising of deep neural network methods is the advanced computing power of modern GPUs running on top of deep learning platforms like TensorFlow or PyTorch. Along with CPUs instances, powerful GPUs are configured in a distributed computing environment where cloud users can utilise PySpark to perform parallel ML tasks. I can name a few popular GPUs available on cloud:
In most use cases of AutoML, CPUs are efficient to perform standard training and inferencing tasks. A GPU cluster is a better choice when we need train complicated deep neural network architectures for specific ML tasks including natural languages processing, image classification, video analyses and voice recognition. The cloud vendors generally maintain separated tracks for each of these deep learning models, for example:
Now that I've gone through some of the powerful capabilities provided by major cloud vendors, let’s discuss auto-scaling and cost-optimisation. For large systems with millions of users and increasing demand, it's crucial to have the ability to automatically scale up or down without any disruption to the services. Cloud vendors allow their clients to achieve this goal in an advanced approach to optimise costs compared to maintaining fixed resources locally (waste of resource in low demand and hard to upgrade for unexpected high demand).
For example, AWS or MS Azure Autoscale monitors resources and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. Autoscale here is for both scaling up to avoid overload or scaling down to save money by using only what the client need.
Quality labelled data is very important to the success of the prediction model. Unfortunately, in many cases, the client has historical data but there are no labels associated with it and will need some manual classifications/annotations to create ground-truth for supervised machine learning models. Not all, but some cloud providers including Amazon SageMaker and Google Vertex AI provide labelling services with public (Amazon Mechanical Turk) or private workforce.
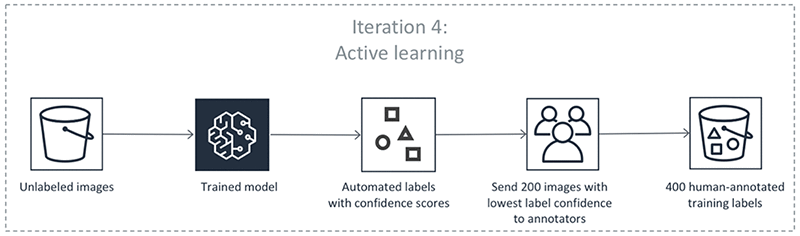
Exceptionally, AWS SageMaker introduced the automate data labelling with active learning4. Active learning is a technique that identifies data that should be labelled by your workers. Automated data labelling helps to reduce the cost and time that it takes to label your dataset compared to using only humans. Even though the built-in active learning method is considered basic (e.g. uncertainty based on confidence score which is prone to query outliers), I still think this is a great effort to optimise all aspects of ML/AI lifecycle by AWS SageMaker.
I hope this gives you a general picture of AI/ML capabilities provided by leading cloud vendors. Some features including one-click deployment or drag-n-drop ML flow designer might sound too good to be true however, they are just at the very basic level of predictive analytics to deal with standard tasks like single value classification and regression.
To sum up, even at a basic level, it's good to have AutoML integrated in the cloud services to build rapid predictive models for popular machine learning tasks. More complicated solutions may still require experienced data scientists to work on SDK within a cloud environment.
Data science teams will have more time to focus on developing the ML algorithms. Other tasks including feature engineering, experiment management, model deployment and auto updating are efficiently managed by cloud-based environments.
1 https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century
2 Source: https://aws.amazon.com/sagemaker/autopilot/
3 https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-xai-overview
4 https://docs.aws.amazon.com/sagemaker/latest/dg/sms-automated-labeling.html
Copyright © Tridant Pty Ltd.