If you are thinking of migrating your data to the cloud or are new to the cloud, it is important to pivot your thinking in terms of how you will firstly store data and then use the data in the cloud. You should consider the following:
What data should you migrate to the cloud and in what order?
How much data can, and should you migrate to the cloud?
How will you share the information and insights both internally in your organisation and externally with your partners, customers, regulators, and the general public (if needed)?
Are there opportunities to share data with external agencies and receive data from partners and from the market for better collaboration in a more modern and secure way?
Are there opportunities to monetise your data?
As you're building a business case in your organization to move to the cloud, it is important to understand the situation as it is today on premises vs in the cloud. In the on premise world, you would have invested significant capex to obtain the required hardware (servers) and software licenses, and you would have tried to maximise its usage. You will also be paying for hardware and software ongoing maintenance services along with database administration services.
On the other hand, in the cloud world, the cost of entry is comparatively lower, and costs are opex oriented. The cloud’s basic building blocks are storage and compute, and you will only pay forwhat you use and when you use it. The Pay-As-You-Go model works well for companies that would like to start small to understand how the model works and then grow. The capacity model where you pay in advance for a certain amount of storage and compute works well when you have a good understanding on what your usage is likely to be. The capacity model usually provides significant discounts over the Pay-As-You-Go price and brings about other benefits like priority support from the vendor, training and enablement and rubber stamping of architecture or implementation methodologies by the vendor.
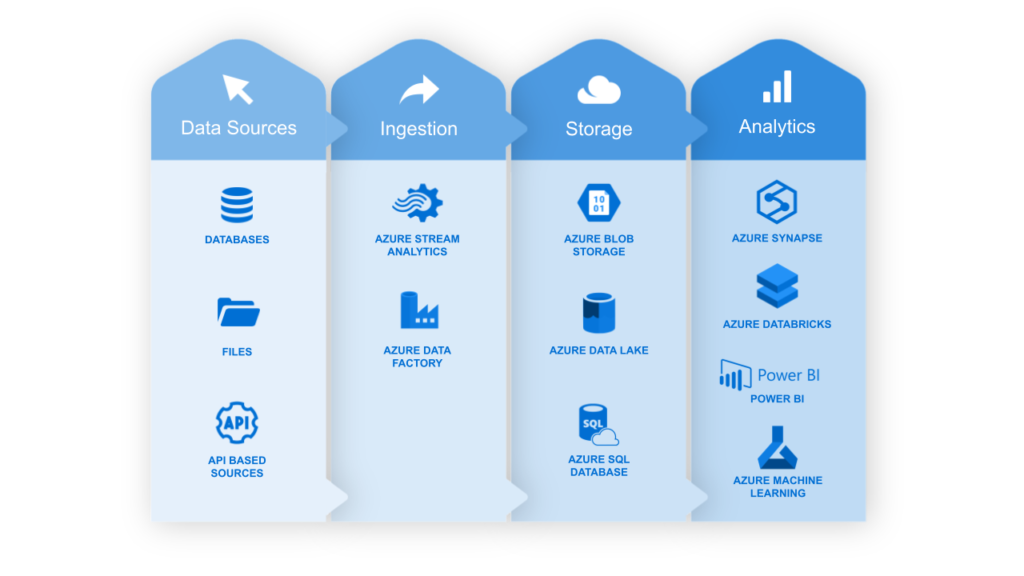
Microsoft Azure’s cloud data ecosystem
The main components of Azure’s Data ecosystem are shown below:
Data Sources:
This is your business data such as your ERP system, CRM system and so on. This can be supplemented with external data that may add value when combined with your internal data.
Business data sources can typically come in various formats and types like On-premise vs Cloud, Structured vs Semi-Structured vs Unstructured Data, Databases vs Files vs APIs.
Data Ingestion and Orchestration:
Once you have identified the business data that you would like to report on or analyse, you typically ingest it into a single repository and combine data from various sources together to get a holistic picture of your customer, product, or business processes.
The Azure family tools that help you with this are:
Azure Data Factory
Azure Stream Analytics
Data Storage
The central repository of data can be created and maintained using various methodologies and formats. You may want quick real-time access to your data, so a Data Lake methodology is more suitable, whereas the more curated and modelled Data Warehouse is suitable for holistic insights and multiple use cases such as reporting, insights and self-service.
The Azure family tools that help you with this are:
Azure Blob Storage
Azure Data Lake
Azure SQL Database
Data Analytics
Once your business data has been ingested into a central repository and prepared for reporting and analytics, now it is time to leverage powerful tools out there to gain valuable insight on your customer, product or business process. You may also want to predict future outcomes and prescribe how your business may react to them.
The Azure family tools that help you with this are:
Azure Synapse
Azure Databricks
Power BI
Azure Machine Learning
Each of these has a role to play in your overall data architecture as your organisation grows and matures in the Data & Analytics space.
We will now look to demystify and learn the purpose of each of the above-mentioned Azure Data technologies and look to see where they can add business value.
1. Azure Data Factory
Azure Data Factory is a cloud-managed service that is used to orchestrate the data copying between different relational and non-relational data sources, hosted in the cloud or on-premise, and transforming it to meet the business requirements. It is responsible for the cloud-based ETL, ELT and Data ingestion processes using scheduled data-driven workflows.
Some business benefits of using Azure Data Factory are:
Benefits
Enterprise ready: ADF is a cloud-based solution that works with both on-premise and cloud-based data stores. It gives cost-effective and scalable solutions.
Enterprise data ready: ADF comes with many built-in connectors that make it effortless to integrate, and ingest data from, familiar enterprise data sources.
Code-free transformation: ADF has mapping data flows with a UI-based wizard for creating data transformation.
Run code on any Azure compute: ADF has many supported compute environments and activities that make task dispatch and execution easy, within data pipelines.
Run existing Microsoft SSIS packages: ADF can run SSIS packages in an Azure-SSIS integration runtime.
Seamless data ops: ADF makes data pipeline operations easy with automated deploy, and reusable templates. You can integrate with Azure DevOps or GitHub workflows.
Secure data integration: ADF gives managed virtual networks to simplify your networking and protect against data exfiltration.
2. Azure Stream Analytics
Azure Stream Analytics is Microsoft’s serverless real-time analytics offering for complex event processing. It enables customers to unlock valuable insights and gain a competitive advantage by harnessing the power of big data.
Benefits
Fully integrated with Azure ecosystem:Whether you have millions of IoT devices streaming data to Azure IoT Hub or have apps sending critical telemetry events to Azure Event Hubs, it only takes a few clicks to connect multiple sources and sinks to create an end-to-end pipeline. Azure Stream Analytics provides best-in-class integration to store your output, like Azure SQL Database, Azure Cosmos DB, Azure Data Lake Store. It also enables you to trigger custom workflows downstream with Azure Functions, Azure Service Bus Queues, Azure Service Bus Topics, or create real-time dashboards using Power BI.
Developer productivity: One of the biggest advantages of Stream Analytics is the simple SQL-based query language with its powerful temporal constraints to analyse data in motion.
Intelligent edge: Most data becomes useless just seconds after it’s generated. In many cases, processing data closer to the point of generation is becoming more and more critical. This allows for lower bandwidth costs and ability of a system to function even with intermittent connectivity. Azure Stream Analytics on IoT Edge enables you to deploy real-time analytics closer to IoT devices so that you can unlock the full value of device-generated data.
Scale instantly: Stream Analytics is a fully managed serverless (PaaS) offering on Azure. There is no infrastructure to worry about, and no servers, virtual machines, or clusters to manage. We do all the heavy lifting for you in the background. You can instantly scale up or scale out the processing power from one to hundreds of streaming units for any job.
Reliable: Stream Analytics guarantees “exactly once” event processing and at least once delivery of events. It has built-in recovery capabilities in case the delivery of an event fails. So, you never have to worry about your events getting dropped.
Easily leverage the power of machine learning: Azure Stream Analytics offers real-time event scoring by integrating with Azure Machine Learning solutions. Additionally, Stream Analytics offers built-in support for commonly used scenarios such as anomaly detection, which helps reduce the complexity associated with building and deploying an ML model in your hot-path analytics pipeline to a simple function call. Users can easily detect common anomalies such as spikes, dips, slow positive or negative trends with these online learning and scoring models.
3. Azure Blob Storage
Azure Blob storage is a service for storing large amounts of structured, semi-structured or unstructured data, such as business files, text, images, shape files, audio, video, and IOT data. You can use Blob storage to expose data publicly to the world or to store application data securely and privately.
There are 3 types of Blobs, and they are used for various purposes as explained below:
Append Blobs Append blobs are specifically designed for use with append operations. The most common use of an append blob is for storage and updating of log files. Blocks may be appended to the end of an append blob, but previously existing blocks may not be modified or deleted.
Just as with block blobs, an append blob may contain up to 50,000 blocks, each up to 4 MiB.
Block Blobs Block blobs are subdivided into blocks and are primarily intended for the storage of media files, documents, text files, and binary files. Blocks can be of varying sizes, with a maximum size of 4000 MiB (mebibytes) per block (in the most current Azure version). There may be anywhere up to 50,000 blocks per blob, giving a maximum block blob size of around 4.75 TiB (tebibytes).
Page Blobs A page blob is intended for read and write operations. A page blob is an assembly of 512-byte pages, with a maximum page blob size of 8TiB. Page blobs are useful for the storage of items such as operating systems and disaster recovery data.
There are 3 tiers of Blob storage available based on the frequency of access to the data and they are priced accordingly. The less often you need to access the data the cheaper the storage is based on these tiers: - Hot: Hot storage is for the most frequently accessed data. It has the highest storage cost but the lowest transaction cost of the three tiers. Hot blob storage is always online.
- Cool: Cool storage is for data that is periodically accessed, but not with great frequency. Specifically, cool storage is appropriate when data is not accessed more than once every 30 days. Cool storage has a lower storage cost than hot storage, but higher transaction costs. As with hot storage, cool storage data is always online.
- Archival: Archival storage is for data that requires long-term storage and very infrequent access (i.e. less than once every 180 days). It has the lowest storage cost and the highest transactional cost. Archival data storage is always offline. Users can optimize their costs through use of data lifecycle policies.
Benefits
The benefits of using Azure Blob Storage are:
Low-cost storage
Ability to store any type of data – structured, semi-structured and unstructured.
Pricing is available based on how often you need to access the data.
Easy way to get your data from on-premise to the cloud either temporarily or permanently as it goes further downstream to a Database or other Analytics applications.
Secure, role-based access is available.
4. Azure Data Lake
Data Lake Storage Gen2 makes Azure Storage the foundation for building enterprise data lakes on Azure. Designed from the start to service multiple petabytes of information while sustaining hundreds of gigabits of throughput, Data Lake Storage Gen2 allows you to easily manage massive amounts of data.
A fundamental part of Data Lake Storage Gen2 is the addition of a hierarchical namespace to Blob storage. The hierarchical namespace organizes objects/files into a hierarchy of directories for efficient data access. A common object store naming convention uses slashes in the name to mimic a hierarchical directory structure.
Data Lake Storage Gen2 builds on Blob storage and enhances performance, management, and security in the following ways:
Performance is optimized because you do not need to copy or transform data as a prerequisite for analysis. Compared to the flat namespace on Blob storage, the hierarchical namespace greatly improves the performance of directory management operations, which improves overall job performance.
Management is easier because you can organize and manipulate files through directories and subdirectories.
Security is enforceable because you can define POSIX permissions on directories or individual files.
Benefits
Scalability Azure Storage is scalable by design whether you access it via Data Lake Storage Gen2 or Blob storage interfaces. It is able to store and serve many exabytes of data. This amount of storage is available with throughput measured in gigabits per second (Gbps) at high levels of input/output operations per second (IOPS). Processing is executed at near-constant per-request latencies that are measured at the service, account, and file levels.
Cost-effectiveness Because Data Lake Storage Gen2 is built on top of Azure Blob Storage, storage capacity and transaction costs are lower. Additionally, features such as the hierarchical namespace significantly improve the overall performance of many analytics jobs. This improvement in performance means that you require less computing power to process the same amount of data, resulting in a lower total cost of ownership (TCO) for the end-to-end analytics job.
One service, multiple concepts Because Data Lake Storage Gen2 is built on top of Azure Blob Storage, multiple concepts can describe the same, shared things.
The following are the equivalent entities, as described by different concepts.
5. Azure SQL Database
Azure SQL Database is a fully managed platform as a service (PaaS) database engine, which means that Microsoft operates SQL Server for you, and ensures its availability and performance. Azure SQL Database handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement. It is always running on the latest stable version of the SQL Server database engine and patched OS with 99.99% availability. PaaS capabilities built into Azure SQL Database enable you to focus on the domain-specific database administration and optimization activities that are critical for your business.
SQL Database enables you to easily define and scale performance within two different purchasing models: a vCore-based purchasing model and a DTU-based purchasing model.
Deployment models
Azure SQL Database provides the following deployment options for a database:
A single database represents a fully managed, isolated database. You might use this option if you have modern cloud applications and microservices that need a single reliable data source. A single database is similar to a contained database in the SQL Server database engine.
An elastic pool is a collection of single databases with a shared set of resources, such as CPU or memory. Single databases can be moved into and out of an elastic pool.
Benefits
Advanced, automated management
Reliable availability
Backed-up and durable
Integrated with Microsoft and Azure ecosystems
Modern scalability
Advanced security
Flexible pricing and service tiers
6. Azure Synapse
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated options – at scale
Features and Benefits:
Synapse was positioned in the market as the evolution of Azure SQL Data Warehouse (SQL DW), bringing together business data storage and macro or Big Data analysis.
Synapse provides a single service for all workloads when processing, managing, and serving data for immediate business intelligence and data prediction needs.
The Predictive capabilities are made possible by its integration with Power BI and Azure Machine Learning, due to Synapse's ability to integrate mathematical machine learning models using the ONNX format.
It provides the freedom to handle and query huge amounts of information either on-demand serverless (a type of deployment that automatically scales power on demand when large amounts of data are available) for data exploration and ad hoc analysis, or with provisioned resources, at scale.
Azure Synapse uses Azure Data Lake Storage Gen2 as a data warehouse and a consistent data model that incorporates administration, monitoring, and metadata management sections.
In the security area, it allows you to protect, monitor, and manage your data and analysis solutions, for example using single sign-on and Azure Active Directory integration.
In terms of programming language support, it offers a choice of several languages such as SQL, Python, .NET, Java, Scala and R. This makes it highly suitable for different analysis workloads and different engineering profiles.
Features are encompassed within the Synapse Analytics Studio that makes it easy to integrate Artificial Intelligence, Machine Learning, IoT, intelligent applications or business intelligence, all within the same unified platform.
7. Azure Databricks
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks offers three environments for developing data-intensive applications: Databricks SQL, Databricks Data Science & Engineering, and Databricks Machine Learning.
Databricks SQL provides an easy-to-use platform for analysts who want to run SQL queries on their data lake, create multiple visualization types to explore query results from different perspectives, and build and share dashboards.
Databricks Data Science & Engineering provides an interactive workspace that enables collaboration between data engineers, data scientists, and machine learning engineers. For a big data pipeline, the data (raw or structured) is ingested into Azure through Azure Data Factory in batches, or streamed near real-time using Apache Kafka, Event Hub, or IoT Hub. This data lands in a data lake for long-term persisted storage, in Azure Blob Storage or Azure Data Lake Storage. As part of your analytics workflow, use Azure Databricks to read data from multiple data sources and turn it into breakthrough insights using Spark.
Databricks Machine Learning is an integrated end-to-end machine learning environment incorporating managed services for experiment tracking, model training, feature development and management, and feature and model serving.
Benefits
Integrates easily with the whole Microsoft stack Azure Databricks uses the Azure Active Directory (AAD) security framework. Existing credentials authorization can be utilized, with the corresponding security settings. Access and identity control are all done in the same environment. Using AAD allows easy integration with the entire Azure stack including Data Lake Storage (as a data source or an output), Data Warehouse, Blob storage, and Azure Event Hub.
An extensive list of data connections Aside from those Azure-based sources mentioned, Databricks easily connects to sources including on-premise SQL servers, CSVs, and JSONs. Other data sources include MongoDB, Avro files, and Couchbase. A full list of data sources can be found here.
Familiar languages and environment While Azure Databricks is Spark-based, it allows commonly used programming languages like Python, R, and SQL to be used. These languages are converted in the backend through APIs, to interact with Spark. These save users from having to learn another programming language, such as Scala, for the sole purpose of distributed analytics.
Language
Language API Used
Python
PySpark
R
SparkR or SparkylR
Java
spark.api.java
SQL
Spark SQL
Higher productivity and collaboration Databricks creates an environment that provides workspaces for collaboration (between data scientists, engineers, and business analysts), deploys production jobs (including the use of a scheduler), and has an optimized Databricks engine for running. These interactive workspaces allow multiple members to collaborate for data model creation, machine learning, and data extraction.
8. Power BI
Power BI is Microsoft’s Reporting and Analytics offering that makes it easy for an organisation to report on its key metrics and look for insights hidden in their data.
Power BI can connect to a variety of data sources both on-premise and on the cloud but most importantly connects to your data foundation layer to provide insights.
Power BI has matured well over the years to now become an enterprise reporting and analytics tool. It offers an extended library of visualisations, a powerful language called DAX to create business calculations, and an ability to model your data (connect the dimensions and facts together) to produce meaningful insights.
Benefits
Ability to connect to a variety of data sources Power BI can connect to a variety of data source types that makes it easy for an organisation to either quickly visualise the data to understand more about the data source ad data lying inside it or allows you to connect to a curated data source like a data lake or a data warehouse which may have different types of business data already integrated into it.
A listing of different types of data sources that Power BI can connect to can be found here.
Role-Based Access and Data Security Power BI integrates well with a directory service like Azure Active Directory to establish role-based access and data security. This means that people are only able to see the data that they have explicit access to and based on their data access role. It makes it easier to maintain such an access model as compared to individual user-based access.
Row-level security (RLS) with Power BI can be used to restrict data access for given users. Filters restrict data access at the row level, and you can define filters within roles. In the Power BI service, members of a workspace have access to datasets in the workspace. RLS doesn't restrict this data access.
Self-Service Reporting & Analytics
With adequate training and practice, a business user can be empowered to use Power BI effectively to create reports and find insights. A Power BI developer, after understanding business requirements can prepare a reporting model that is effective and easy to use and hence facilitate the process of self-service reporting and insights. Sometimes more than one Power BI model may be needed to ensure various departmental needs are met and overall organisation-level reporting can be done.
9. Azure Machine Learning
Microsoft Azure Machine Learning is a collection of services and tools intended to help developers train and deploy machine learning models. Microsoft provides these tools and services through its Azure public cloud.
Figure: Machine learning project lifecycle
The Microsoft Azure Machine Learning suite includes an array of tools and services that help facilitate a variety of use cases, personas, and applications. These include:
Azure Machine Learning Workbench
Azure Machine Learning Experimentation Service
Azure Machine Learning Model Management
Synapse ML / MMLSpark
Visual Studio Code Tools for AI
Azure Machine Learning Studio
Benefits:
User friendly Azure ML Learning Studio offers drag-and-drop features, and you can connect structures to create experiments
Ability to develop and deploy across different environments: Visual Studio Code Tools for AI provides a desktop source code editor for Windows, macOS and Linux -- that helps developers create scripts and gather metrics for Azure Machine Learning experiments. Azure Machine Learning Model Management: This service helps developers track and manage model versions; register and store models; process models and dependencies into Docker image files; register those images in their own Docker registry in Azure; and deploy those container images to a wide assortment of computing environments, including IoT edge devices.
Leverage ML as a Service with flexible pricing Microsoft offers Azure ML as a pay-as-you-go service. Azure ML services enable businesses to save on costs and the hassles that go into the purchasing and implementation of big hardware or complex software. With this flexible pricing model, organizations can purchase only the services they need and start building ML apps immediately.
In summary, the move to the cloud will give you access to low-cost, modern and disruptive technologies that likely do not exist on premises. Microsoft Azure’s cloud data ecosystem of tools and Tridant’s team of data and analytics experts are here to help you start and guide you on your cloud data journey.